kubelet volume manager源码分析
kubelet volume manager组件源码分析
- k8s版本:1.20.0
总体
volume模块图
kubelet调用VolumeManager,为pods准备存储设备,存储设备就绪会挂载存储设备到pod所在的节点上,并在容器启动的时候挂载在容器指定的目录中;同时,删除卸载不再使用的存储; kubernetes采用Volume Plugins来实现存储卷的挂载等操作
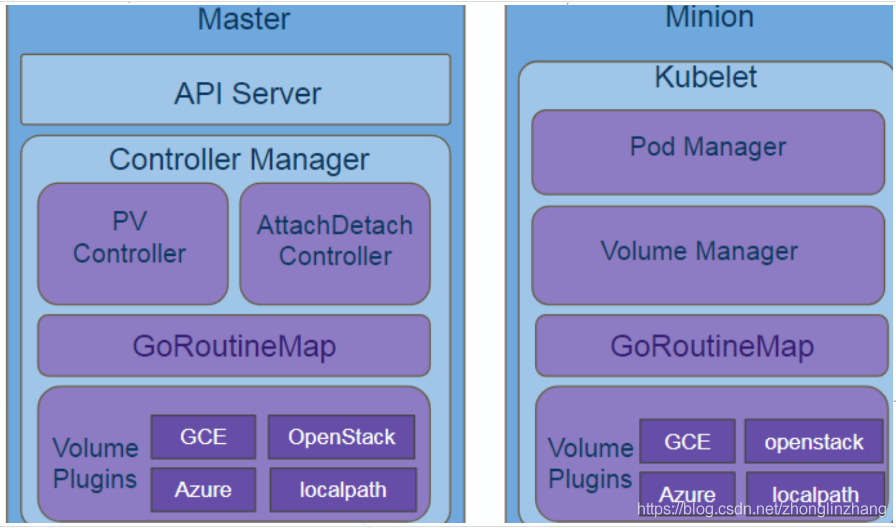
volume manager
源码位置:kubernetes\pkg\kubelet\volumemanager
| |
kubelet会调用VolumeManager,为pods准备存储设备,存储设备就绪会挂载存储设备到pod所在的节点上,并在容器启动的时候挂载在容器指定的目录中;同时,删除卸载不在使用的存储
VolumeManager接口说明
- 运行在kubelet 里让存储Ready的部件,主要是mount/unmount(attach/detach可选)
- pod调度到这个node上后才会有卷的相应操作,所以它的触发端是kubelet(严格讲是kubelet里的pod manager),根据Pod Manager里pod spec里申明的存储来触发卷的挂载操作
- Kubelet会监听到调度到该节点上的pod声明,会把pod缓存到Pod Manager中,VolumeManager通过Pod Manager获取PV/PVC的状态,并进行分析出具体的attach/detach、mount/umount, 操作然后调用plugin进行相应的业务处理
volumeManager结构体
volumeManager结构体实现了VolumeManager接口,主要有两个需要注意:
- desiredStateOfWorld:预期状态,volume需要被attach,哪些pods引用这个volume
- actualStateOfWorld:实际状态,volume已经被atttach哪个node,哪个pod mount volume
desiredStateOfWorld 和 actualStateOfWorld
desiredStateOfWorld为理想的volume情况,它主要是根据podManger获取所有的Pod信息,从中提取Volume信息。
actualStateOfWorld则是实际的volume情况。
desiredStateOfWorldPopulator通过podManager去构建desiredStateOfWorld。
reconciler的工作主要是比较actualStateOfWorld和desiredStateOfWorld的差别,然后进行volume的创建、删除和修改,最后使二者达到一致。
流程
新建
NewVolumeManager中主要构造了几个volume控制器
- volumePluginMgr 和 csiMigratedPluginManager
- desiredStateOfWorldPopulator
- reconciler
| |
启动
kl.volumeManager.Run
| |
启动子模块有
- 如果有volumePlugin(默认安装时没有插件),启动volumePluginMgr
- 启动 desiredStateOfWorldPopulator:从apiserver同步到的pod信息,更新DesiredStateOfWorld
- findAndAddNewPods()
- findAndRemoveDeletedPods() 每隔dswp.getPodStatusRetryDuration时长,进行findAndRemoveDeletedPods()
- 启动 reconciler:预期状态和实际状态的协调者,负责调整实际状态至预期状态
desiredStateOfWorldPopulator
通过populatorLoop()来更新DesiredStateOfWorld
| |
findAndAddNewPods
- 遍历pod manager中所有pod
- 过滤掉Terminated态的pod,进行processPodVolumes,把这些pod添加到desired state of world
就是通过podManager获取所有的pods,然后调用processPodVolumes去更新desiredStateOfWorld。但是这样只能更新新增加的Pods的Volume信息。
| |
processPodVolumes
更新desiredStateOfWorld
| |
findAndRemoveDeletedPods
- 由于findAndRemoveDeletedPods 代价比较高昂,因此会检查执行的间隔时间。
- 遍历desiredStateOfWorld.GetVolumesToMount()的挂载volumes,根据volumeToMount.Pod判断该Volume所属的Pod是否存在于podManager。
- 如果存在podExists,则继续判断pod是否终止:如果pod为终止则忽略
- 根据containerRuntime进一步判断pod中的全部容器是否终止:如果该pod仍有容器未终止,则忽略
- 根据actualStateOfWorld.PodExistsInVolume判断:Actual state没有该pod的挂载volume,但pod manager仍有该pod,则忽略
- 删除管理器中该pod的该挂载卷:desiredStateOfWorld.DeletePodFromVolume(volumeToMount.PodName, volumeToMount.VolumeName)
- 删除管理器中该pod信息(desiredStateOfWorldPopulator.pods[volumeToMount.PodName]):deleteProcessedPod(volumeToMount.PodName)
简单说,对于pod manager已经不存在的pods,findAndRemoveDeletedPods会删除更新desiredStateOfWorld中这些pod和其volume记录
| |
说明:
假如runningPodsFetched不存在,并不会立即马上删除卷信息记录。而是调用dswp.kubeContainerRuntime.GetPods(false)抓取Pod信息,这里是调用kubeContainerRuntime的GetPods函数。因此获取的都是runningPods信息,即正在运行的Pod信息。由于一个volume可以属于多个Pod,而一个Pod可以包含多个container,每个container都可以使用volume,所以他要扫描该volume所属的Pod的container信息,确保没有container使用该volume,才会删除该volume。
desiredStateOfWorld就构建出来了,这是理想的volume状态,这里并没有发生实际的volume的创建删除挂载卸载操作。实际的操作由reconciler.Run(sourcesReady, stopCh)完成。
reconciler
reconciler 调谐器,即按desiredStateOfWorld来同步volume配置操作
主要流程
通过定时任务定期同步,reconcile就是一致性函数,保存desired和actual状态一致。
reconcile首先从actualStateOfWorld获取已经挂载的volume信息,然后查看该volume是否存在于desiredStateOfWorld,假如不存在就卸载。
接着从desiredStateOfWorld获取需要挂载的volumes。与actualStateOfWorld比较,假如没有挂载,则进行挂载。
这样存储就可以加载到主机attach,并挂载到容器目录mount。
| |
CleanupMountPoint -> doCleanupMountPoint
具体volume卸载操作
- 如果是挂载点,则先卸载mounter.Unmount(mountPath)
- os.Remove(mountPath)
| |
mountVolumeFunc
执行plugin的SetUp方法,以及更新actual state of world
pendingOperations
根据pendingOperations: nestedpendingoperations.NewNestedPendingOperations,nestedPendingOperations实现了NestedPendingOperations接口,包括Run方法
路径 pkg/volume/util/nestedpendingoperations/nestedpendingoperations.go
mountAttachVolumes
处理分支:
- Volume is not attached (or doesn’t implement attacher), kubelet attach is disabled, wait for controller to finish attaching volume.
- Volume is not attached to node, kubelet attach is enabled, volume implements an attacher, so attach it
- Volume is not mounted, or is already mounted, but requires remounting
MountVolume
对于文件系统卷类型,operationGenerator.GenerateMountVolumeFunc(waitForAttachTimeout, volumeToMount, actualStateOfWorld) 具体挂载操作 GenerateMountVolumeFunc
| |
NFS的mount setup
- 挂载命令默认使用了系统命令mount
- nfs中为每个volume的挂载目录路径的pluginName是kubernetes.io~nfs
- mount操作的source为nfs server 的 exportPath
- mount操作的target为dir,即pod的nfs卷路径位置nfsMounter.GetPath(),示例见下
| |
nfs的挂载volume路径dir示例: var/lib/kubelet/pods/{podid}//volumes/{pluginName}/{pvname}
| |
mount挂载处理
| |
Kueblet SyncPod
SyncPod上下文
这里先回顾下pod容器创建准备过程,粗体标注为volume相关的处理。
完成创建容器前的准备工作(SyncPod) 在这个方法中,主要完成以下几件事情:
- 如果是删除 pod,立即执行并返回
- 同步 podStatus 到 kubelet.statusManager
- 检查 pod 是否能运行在本节点,主要是权限检查(是否能使用主机网络模式,是否可以以 privileged 权限运行等)。如果没有权限,就删除本地旧的 pod 并返回错误信息
- 创建 containerManagar 对象,并且创建 pod level cgroup,更新 Qos level cgroup
- 如果是 static Pod,就创建或者更新对应的 mirrorPod
- 创建 pod 的数据目录,存放 volume 和 plugin 信息,如果定义了 pv,等待所有的 volume mount 完成(volumeManager 会在后台做这些事情),如果有 image secrets,去 apiserver 获取对应的 secrets 数据
- 然后调用 kubelet.volumeManager 组件,等待它将 pod 所需要的所有外挂的 volume 都准备好。
- 调用 container runtime 的 SyncPod 方法,去实现真正的容器创建逻辑 这里所有的事情都和具体的容器没有关系,可以看到该方法是创建 pod 实体(即容器)之前需要完成的准备工作。
| |
在上面的上下文中,看到了kubelet的syncpod处理,同步 pod 时,等待 pod attach 和 mount 完成
| |
WaitForAttachAndMount
| |
verifyVolumesMountedFunc
- 没有被 mount 的volume 数量为0,表示成功完成挂载
- UnmountedVolumes = expectedVolumes - mountedVolumes
| |