1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
|
/*
Copyright 2014 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package cache
import (
"errors"
"fmt"
"sync"
"k8s.io/apimachinery/pkg/util/sets"
"github.com/golang/glog"
)
// NewDeltaFIFO returns a Store which can be used process changes to items.
//
// keyFunc is used to figure out what key an object should have. (It's
// exposed in the returned DeltaFIFO's KeyOf() method, with bonus features.)
//
// 'compressor' may compress as many or as few items as it wants
// (including returning an empty slice), but it should do what it
// does quickly since it is called while the queue is locked.
// 'compressor' may be nil if you don't want any delta compression.
//
// 'keyLister' is expected to return a list of keys that the consumer of
// this queue "knows about". It is used to decide which items are missing
// when Replace() is called; 'Deleted' deltas are produced for these items.
// It may be nil if you don't need to detect all deletions.
// TODO: consider merging keyLister with this object, tracking a list of
// "known" keys when Pop() is called. Have to think about how that
// affects error retrying.
// TODO(lavalamp): I believe there is a possible race only when using an
// external known object source that the above TODO would
// fix.
//
// Also see the comment on DeltaFIFO.
func NewDeltaFIFO(keyFunc KeyFunc, compressor DeltaCompressor, knownObjects KeyListerGetter) *DeltaFIFO {
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: keyFunc,
deltaCompressor: compressor,
knownObjects: knownObjects,
}
f.cond.L = &f.lock
return f
}
// DeltaFIFO is like FIFO, but allows you to process deletes.
//
// DeltaFIFO is a producer-consumer queue, where a Reflector is
// intended to be the producer, and the consumer is whatever calls
// the Pop() method.
//
// DeltaFIFO solves this use case:
// * You want to process every object change (delta) at most once.
// * When you process an object, you want to see everything
// that's happened to it since you last processed it.
// * You want to process the deletion of objects.
// * You might want to periodically reprocess objects.
//
// DeltaFIFO's Pop(), Get(), and GetByKey() methods return
// interface{} to satisfy the Store/Queue interfaces, but it
// will always return an object of type Deltas.
//
// A note on threading: If you call Pop() in parallel from multiple
// threads, you could end up with multiple threads processing slightly
// different versions of the same object.
//
// A note on the KeyLister used by the DeltaFIFO: It's main purpose is
// to list keys that are "known", for the purpose of figuring out which
// items have been deleted when Replace() or Delete() are called. The deleted
// object will be included in the DeleteFinalStateUnknown markers. These objects
// could be stale.
//
// You may provide a function to compress deltas (e.g., represent a
// series of Updates as a single Update).
type DeltaFIFO struct {
// lock/cond protects access to 'items' and 'queue'.
// 读写锁,因为涉及到同时读写,读写锁性能要高
lock sync.RWMutex
// 给Pop()接口使用,在没有对象的时候可以阻塞,内部锁复用读写锁
cond sync.Cond
// We depend on the property that items in the set are in
// the queue and vice versa, and that all Deltas in this
// map have at least one Delta.
// 存储对象
// 这个应该是Store的本质了,按照kv的方式存储对象,但是存储的是对象的Deltas数组
items map[string]Deltas
// 队列
//这个是为先入先出实现的,存储的就是对象的键
queue []string
// populated is true if the first batch of items inserted by Replace() has been populated
// or Delete/Add/Update was called first.
// 通过Replace()接口将第一批对象放入队列,或者第一次调用增、删、改接口时标记为true
populated bool
// initialPopulationCount is the number of items inserted by the first call of Replace()
// 通过Replace()接口将第一批对象放入队列的对象数量
initialPopulationCount int
// keyFunc is used to make the key used for queued item
// insertion and retrieval, and should be deterministic.
// 对象键计算函数
//MetaNamespaceKeyFunc
//meta.GetNamespace() + "/" + meta.GetName()
keyFunc KeyFunc
// deltaCompressor tells us how to combine two or more
// deltas. It may be nil.
deltaCompressor DeltaCompressor
// knownObjects list keys that are "known", for the
// purpose of figuring out which items have been deleted
// when Replace() or Delete() is called.
// 前面介绍就是为了这是用,该对象指向的就是Indexer,
knownObjects KeyListerGetter
// Indication the queue is closed.
// Used to indicate a queue is closed so a control loop can exit when a queue is empty.
// Currently, not used to gate any of CRED operations.
// 是否已经关闭的标记
closed bool
// 专为关闭设计的锁,这里非读写锁,可能不是读多写少场景
closedLock sync.Mutex
}
var (
_ = Queue(&DeltaFIFO{}) // DeltaFIFO is a Queue
)
var (
// ErrZeroLengthDeltasObject is returned in a KeyError if a Deltas
// object with zero length is encountered (should be impossible,
// even if such an object is accidentally produced by a DeltaCompressor--
// but included for completeness).
ErrZeroLengthDeltasObject = errors.New("0 length Deltas object; can't get key")
)
// Close the queue.
func (f *DeltaFIFO) Close() {
f.closedLock.Lock()
defer f.closedLock.Unlock()
f.closed = true
f.cond.Broadcast()
}
// KeyOf exposes f's keyFunc, but also detects the key of a Deltas object or
// DeletedFinalStateUnknown objects.
func (f *DeltaFIFO) KeyOf(obj interface{}) (string, error) {
// 先用Deltas做一次强行转换
//DeltaFIFO的计算对象键的方式为什么要先做一次Deltas的类型转换呢?
//原因很简单,那就是从DeltaFIFO.Pop()出去的对象很可能还要再添加进来(比如处理失败需要再放进来),
//此时添加的对象就是已经封装好的Deltas。
if d, ok := obj.(Deltas); ok {
if len(d) == 0 {
return "", KeyError{obj, ErrZeroLengthDeltasObject}
}
// 只用最新版本的对象就可以了
// 即该Deltas数组中最后一个元素
obj = d.Newest().Object
}
if d, ok := obj.(DeletedFinalStateUnknown); ok {
return d.Key, nil
}
//MetaNamespaceKeyFunc
//meta.GetNamespace() + "/" + meta.GetName()
return f.keyFunc(obj)
}
// Return true if an Add/Update/Delete/AddIfNotPresent are called first,
// or an Update called first but the first batch of items inserted by Replace() has been popped
func (f *DeltaFIFO) HasSynced() bool {
f.lock.Lock()
defer f.lock.Unlock()
// 这里就比较明白了,一次同步全量对象后,并且全部Pop()出去才能算是同步完成
// 其实这里所谓的同步就是全量内容已经进入Indexer,Indexer已经是系统中对象的全量快照了
return f.populated && f.initialPopulationCount == 0
}
// Add inserts an item, and puts it in the queue. The item is only enqueued
// if it doesn't already exist in the set.
func (f *DeltaFIFO) Add(obj interface{}) error {
f.lock.Lock()
defer f.lock.Unlock()
// 队列第一次写入操作都要设置标记
f.populated = true
return f.queueActionLocked(Added, obj)
}
// Update is just like Add, but makes an Updated Delta.
func (f *DeltaFIFO) Update(obj interface{}) error {
f.lock.Lock()
defer f.lock.Unlock()
// 队列第一次写入操作都要设置标记
f.populated = true
return f.queueActionLocked(Updated, obj)
}
// Delete is just like Add, but makes an Deleted Delta. If the item does not
// already exist, it will be ignored. (It may have already been deleted by a
// Replace (re-list), for example.
func (f *DeltaFIFO) Delete(obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
f.lock.Lock()
defer f.lock.Unlock()
// 队列第一次写入操作都要设置标记
f.populated = true
// 此处是需要注意的,knownObjects就是Indexer,里面存有已知全部的对象
if f.knownObjects == nil {
// 在没有Indexer的条件下只能通过自己存储的对象查一下
if _, exists := f.items[id]; !exists {
// Presumably, this was deleted when a relist happened.
// Don't provide a second report of the same deletion.
return nil
}
} else {
// We only want to skip the "deletion" action if the object doesn't
// exist in knownObjects and it doesn't have corresponding item in items.
// Note that even if there is a "deletion" action in items, we can ignore it,
// because it will be deduped automatically in "queueActionLocked"
// 自己(itemsExist)和Indexer里面(exists)有任何一个有这个对象就算存在
_, exists, err := f.knownObjects.GetByKey(id)
_, itemsExist := f.items[id]
if err == nil && !exists && !itemsExist {
// Presumably, this was deleted when a relist happened.
// Don't provide a second report of the same deletion.
// TODO(lavalamp): This may be racy-- we aren't properly locked
// with knownObjects.
return nil
}
}
return f.queueActionLocked(Deleted, obj)
}
// AddIfNotPresent inserts an item, and puts it in the queue. If the item is already
// present in the set, it is neither enqueued nor added to the set.
//
// This is useful in a single producer/consumer scenario so that the consumer can
// safely retry items without contending with the producer and potentially enqueueing
// stale items.
//
// Important: obj must be a Deltas (the output of the Pop() function). Yes, this is
// different from the Add/Update/Delete functions.
// 添加不存在的对象
func (f *DeltaFIFO) AddIfNotPresent(obj interface{}) error {
// 这个要求放入的必须是Deltas数组,就是通过Pop()弹出的对象
deltas, ok := obj.(Deltas)
if !ok {
return fmt.Errorf("object must be of type deltas, but got: %#v", obj)
}
// 多个Delta都是一个对象,所以用最新的就可以了
id, err := f.KeyOf(deltas.Newest().Object)
if err != nil {
return KeyError{obj, err}
}
f.lock.Lock()
defer f.lock.Unlock()
f.addIfNotPresent(id, deltas)
return nil
}
// addIfNotPresent inserts deltas under id if it does not exist, and assumes the caller
// already holds the fifo lock.
// 这个是添加不存在对象的实现
func (f *DeltaFIFO) addIfNotPresent(id string, deltas Deltas) {
f.populated = true
// 这里判断的对象是否存在
if _, exists := f.items[id]; exists {
return
}
// 放入队列中
f.queue = append(f.queue, id)
f.items[id] = deltas
f.cond.Broadcast()
}
// re-listing and watching can deliver the same update multiple times in any
// order. This will combine the most recent two deltas if they are the same.
func dedupDeltas(deltas Deltas) Deltas {
// 小于2个delta,那就是1个呗,没啥好合并的
n := len(deltas)
if n < 2 {
return deltas
}
// 取出最后两个
a := &deltas[n-1]
b := &deltas[n-2]
// 判断如果是重复的,那就删除这两个delta把合并后的追加到Deltas数组尾部
if out := isDup(a, b); out != nil {
// 使用deltas 前n-2 元素构造d,然后再把合并后的 out追加
d := append(Deltas{}, deltas[:n-2]...)
return append(d, *out)
}
return deltas
}
// If a & b represent the same event, returns the delta that ought to be kept.
// Otherwise, returns nil.
// TODO: is there anything other than deletions that need deduping?
// 判断两个Delta是否是重复的
func isDup(a, b *Delta) *Delta {
// 只有一个判断,只能判断是否为删除类操作,和我们上面的判断相同
// 这个函数的本意应该还可以判断多种类型的重复,当前来看只能有删除这一种能够合并
// 只合并obj前后操作类型都是delete的(即为重复)
if out := isDeletionDup(a, b); out != nil {
return out
}
// TODO: Detect other duplicate situations? Are there any?
return nil
}
// keep the one with the most information if both are deletions.
// 判断是否为删除类的重复
func isDeletionDup(a, b *Delta) *Delta {
// 二者都是删除那肯定有一个是重复的
if b.Type != Deleted || a.Type != Deleted {
return nil
}
// Do more sophisticated checks, or is this sufficient?
// 理论上返回最后一个比较好,但是对象已经不再系统监控范围,前一个删除状态是好的
if _, ok := b.Object.(DeletedFinalStateUnknown); ok {
return a
}
return b
}
// willObjectBeDeletedLocked returns true only if the last delta for the
// given object is Delete. Caller must lock first.
func (f *DeltaFIFO) willObjectBeDeletedLocked(id string) bool {
deltas := f.items[id]
return len(deltas) > 0 && deltas[len(deltas)-1].Type == Deleted
}
// queueActionLocked appends to the delta list for the object, calling
// f.deltaCompressor if needed. Caller must lock first.
// 从函数名称来看把“动作”放入队列中,这个动作就是DeltaType,而且已经加锁了
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
// 1 计算资源对象的key
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// If object is supposed to be deleted (last event is Deleted),
// then we should ignore Sync events, because it would result in
// recreation of this object.
// 2 如果操作类型是Sync,而对象被删除,则忽略Sync事件,直接返回
// 如果是同步,并且对象未来会被删除,那么就直接返回,没必要记录这个动作了
// 肯定有人会问为什么Add/Delete/Update这些动作可以,因为同步对于已经删除的对象是没有意义的
// 已经删除的对象后续跟添加、更新有可能,因为同名的对象又被添加了,删除也是有可能
// 删除有些复杂
if actionType == Sync && f.willObjectBeDeletedLocked(id) {
return nil
}
// 3 构造Delta{actionType, obj},添加到newDeltas 的items[id]
// 同一个对象的多次操作,所以要追加到Deltas数组f.items[id]中
newDeltas := append(f.items[id], Delta{actionType, obj})
// 4 去重操作
// 合并操作,去掉冗余的delta
newDeltas = dedupDeltas(newDeltas)
if f.deltaCompressor != nil {
newDeltas = f.deltaCompressor.Compress(newDeltas)
}
// 5. 如果有newDeltas,则通知所有消费者,解除阻塞
// 判断对象是否已经存在
_, exists := f.items[id]
// 合并后操作有可能变成没有Delta么?后面的代码分析来看应该不会,所以暂时不知道这个判断目的
if len(newDeltas) > 0 {
// 如果对象没有存在过,那就放入队列中,如果存在说明已经在queue中了,也就没必要再添加了
// f.queue 只保存 obj的id,即key
if !exists {
f.queue = append(f.queue, id)
}
// 更新Deltas数组,通知所有调用Pop()的消费者模块
f.items[id] = newDeltas
f.cond.Broadcast()
} else if exists {
// The compression step removed all deltas, so
// we need to remove this from our map (extra items
// in the queue are ignored if they are not in the
// map).
// 直接把对象删除,这段代码不知道什么条件会进来,因为dedupDeltas()肯定有返回结果的
// 这个分支不是消费者模块处理的,直接在delta_fifo处理了
delete(f.items, id)
}
return nil
}
// List returns a list of all the items; it returns the object
// from the most recent Delta.
// You should treat the items returned inside the deltas as immutable.
func (f *DeltaFIFO) List() []interface{} {
f.lock.RLock()
defer f.lock.RUnlock()
return f.listLocked()
}
func (f *DeltaFIFO) listLocked() []interface{} {
list := make([]interface{}, 0, len(f.items))
for _, item := range f.items {
// Copy item's slice so operations on this slice (delta
// compression) won't interfere with the object we return.
item = copyDeltas(item)
list = append(list, item.Newest().Object)
}
return list
}
// ListKeys returns a list of all the keys of the objects currently
// in the FIFO.
func (f *DeltaFIFO) ListKeys() []string {
f.lock.RLock()
defer f.lock.RUnlock()
list := make([]string, 0, len(f.items))
for key := range f.items {
list = append(list, key)
}
return list
}
// Get returns the complete list of deltas for the requested item,
// or sets exists=false.
// You should treat the items returned inside the deltas as immutable.
//Get返回请求项的完整deltas列表,或不存在,则将集合exists=false。
//您应该将delta中返回的项视为不可变的。
// 获取对象接口,这个有意思哈,用对象获取对象?如果说用Service对象获取Pod对象是不是就能接受了?
// 因为他们的对象键是相同的
func (f *DeltaFIFO) Get(obj interface{}) (item interface{}, exists bool, err error) {
key, err := f.KeyOf(obj)
if err != nil {
return nil, false, KeyError{obj, err}
}
return f.GetByKey(key)
}
// GetByKey returns the complete list of deltas for the requested item,
// setting exists=false if that list is empty.
// You should treat the items returned inside the deltas as immutable.
// 通过对象键获取对象
func (f *DeltaFIFO) GetByKey(key string) (item interface{}, exists bool, err error) {
f.lock.RLock()
defer f.lock.RUnlock()
d, exists := f.items[key]
if exists {
// Copy item's slice so operations on this slice (delta
// compression) won't interfere with the object we return.
d = copyDeltas(d)
}
return d, exists, nil
}
// Checks if the queue is closed
// 判断是否关闭
func (f *DeltaFIFO) IsClosed() bool {
f.closedLock.Lock()
defer f.closedLock.Unlock()
if f.closed {
return true
}
return false
}
// Pop blocks until an item is added to the queue, and then returns it. If
// multiple items are ready, they are returned in the order in which they were
// added/updated. The item is removed from the queue (and the store) before it
// is returned, so if you don't successfully process it, you need to add it back
// with AddIfNotPresent().
// process function is called under lock, so it is safe update data structures
// in it that need to be in sync with the queue (e.g. knownKeys). The PopProcessFunc
// may return an instance of ErrRequeue with a nested error to indicate the current
// item should be requeued (equivalent to calling AddIfNotPresent under the lock).
//
// Pop returns a 'Deltas', which has a complete list of all the things
// that happened to the object (deltas) while it was sitting in the queue.
// 对queue中的资源对象数据进行process处理
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
// DeltaFIFO 处理,加锁
f.lock.Lock()
defer f.lock.Unlock()
for {
// 队列中有数据么?
for len(f.queue) == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the f.closed is set and the condition is broadcasted.
// Which causes this loop to continue and return from the Pop().
// 看来是先判断的是否有数据,后判断是否关闭,这个和chan像
if f.IsClosed() {
return nil, FIFOClosedError
}
// 没数据那就等待
// 阻塞处理,直到队列有数据添加,此时len(f.queue) > 0, 跳出该for{},执行后续pop处理流程
f.cond.Wait()
}
// 取出第一个对象
// 取出id 即object的key
id := f.queue[0]
// 数组缩小,相当于把数组中的第一个元素弹出去了
// 去掉一个pod的id,更新queue
f.queue = f.queue[1:]
// 取出对象,因为queue中存的是对象键
// 根据id 检索item 即某object所有的事件Deltas
item, ok := f.items[id]
// 同步对象计数减一,当减到0就说明外部已经全部同步完毕了
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
// 对象不存在,这个是什么情况?貌似我们在合并对象的时候代码上有这个逻辑,估计永远不会执行
if !ok {
// Item may have been deleted subsequently.
continue
}
// 把对象删除
// 删除要处理的item的Deltas
delete(f.items, id)
// Pop()需要传入一个回调函数,用于处理对象
// 处理该id-object的所有事件Deltas
err := process(item)
// 如果需要重新入队列,那就重新入队列
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
// Don't need to copyDeltas here, because we're transferring
// ownership to the caller.
return item, err
}
}
// Replace will delete the contents of 'f', using instead the given map.
// 'f' takes ownership of the map, you should not reference the map again
// after calling this function. f's queue is reset, too; upon return, it
// will contain the items in the map, in no particular order.
func (f *DeltaFIFO) Replace(list []interface{}, resourceVersion string) error {
f.lock.Lock()
defer f.lock.Unlock()
keys := make(sets.String, len(list))
// 遍历所有的输入目标
for _, item := range list {
// 计算目标键
key, err := f.KeyOf(item)
if err != nil {
return KeyError{item, err}
}
// 记录处理过的目标键,采用set存储,是为了后续快速查找
keys.Insert(key)
// 因为输入是目标全量,所以每个目标相当于重新同步了一次
// 每个obj进行同步
if err := f.queueActionLocked(Sync, item); err != nil {
return fmt.Errorf("couldn't enqueue object: %v", err)
}
}
// 如果没有存储的话,自己存储的就是所有的老对象,目的要看看哪些老对象不在全量集合中,那么就是删除的对象了
if f.knownObjects == nil {
// Do deletion detection against our own list.
// 遍历所有的元素
for k, oldItem := range f.items {
// 这个目标在输入的对象中存在就可以忽略
// 因为输入对象keys是要更新替换(replace)到存储(indexer)中的obj
if keys.Has(k) {
continue
}
// 输入对象中没有,说明对象已经被删除了
var deletedObj interface{}
if n := oldItem.Newest(); n != nil {
deletedObj = n.Object
}
// 终于看到哪里用到DeletedFinalStateUnknown了,队列中存储对象的Deltas数组中
// 可能已经存在Delete了,避免重复,采用DeletedFinalStateUnknown这种类型
// DeletedFinalStateUnknown 状态:是delat_fifo本地检查出该obj要删除,但是没有从list-watch到这个ojb的删除事件(可能丢失或延时)
if err := f.queueActionLocked(Deleted, DeletedFinalStateUnknown{k, deletedObj}); err != nil {
return err
}
}
// 如果populated还没有设置,说明是第一次并且还没有任何修改操作执行过
// 队列中第1次输入数据,设置标志符号和initialPopulationCount
if !f.populated {
f.populated = true
f.initialPopulationCount = len(list)
}
return nil
}
// Detect deletions not already in the queue.
// TODO(lavalamp): This may be racy-- we aren't properly locked
// with knownObjects. Unproven.
// 下面处理的就是检测某些目标删除但是Delta没有在队列中
// 从存储中获取所有对象键
knownKeys := f.knownObjects.ListKeys()
queuedDeletions := 0
for _, k := range knownKeys {
// knownKeys存储的对象还在目标对象keys中,那就忽略
if keys.Has(k) {
continue
}
// 获取待deletedObj对象
deletedObj, exists, err := f.knownObjects.GetByKey(k)
if err != nil {
deletedObj = nil
glog.Errorf("Unexpected error %v during lookup of key %v, placing DeleteFinalStateUnknown marker without object", err, k)
} else if !exists {
deletedObj = nil
glog.Infof("Key %v does not exist in known objects store, placing DeleteFinalStateUnknown marker without object", k)
}
// 累积删除的对象数量
queuedDeletions++
// 把对象删除的Delta放入队列
if err := f.queueActionLocked(Deleted, DeletedFinalStateUnknown{k, deletedObj}); err != nil {
return err
}
}
// 和上面的代码差不多,只是计算initialPopulationCount值的时候增加了删除对象的数量
if !f.populated {
f.populated = true
f.initialPopulationCount = len(list) + queuedDeletions
}
return nil
}
// Resync will send a sync event for each item
// 重新同步,这个在cache实现是空的,这里面有具体实现
// 把knownObjects的objs同步更新到delta_fifo中
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
// 如果没有Indexer那么重新同步是没有意义的,因为连同步了哪些对象都不知道
// 列举Indexer里面所有的对象键
keys := f.knownObjects.ListKeys()
// 遍历对象键,为每个对象产生一个同步的Delta
for _, k := range keys {
// 具体对象同步实现接口
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
return nil
}
func (f *DeltaFIFO) syncKey(key string) error {
f.lock.Lock()
defer f.lock.Unlock()
return f.syncKeyLocked(key)
}
// 具体对象同步实现接口
func (f *DeltaFIFO) syncKeyLocked(key string) error {
// 获取对象
obj, exists, err := f.knownObjects.GetByKey(key)
if err != nil {
glog.Errorf("Unexpected error %v during lookup of key %v, unable to queue object for sync", err, key)
return nil
} else if !exists {
glog.Infof("Key %v does not exist in known objects store, unable to queue object for sync", key)
return nil
}
// If we are doing Resync() and there is already an event queued for that object,
// we ignore the Resync for it. This is to avoid the race, in which the resync
// comes with the previous value of object (since queueing an event for the object
// doesn't trigger changing the underlying store <knownObjects>.
// 计算对象的键值,有人会问对象键不是已经传入了么?那个是存在Indexer里面的对象键,可能与这里的计算方式不同
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// 对象已经在存在,说明后续会通知对象的新变化,所以再加更新也没意义
if len(f.items[id]) > 0 {
return nil
}
// 添加对象同步的这个Delta
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
return nil
}
// A KeyListerGetter is anything that knows how to list its keys and look up by key.
type KeyListerGetter interface {
KeyLister
KeyGetter
}
// A KeyLister is anything that knows how to list its keys.
type KeyLister interface {
ListKeys() []string
}
// A KeyGetter is anything that knows how to get the value stored under a given key.
type KeyGetter interface {
GetByKey(key string) (interface{}, bool, error)
}
// DeltaCompressor is an algorithm that removes redundant changes.
type DeltaCompressor interface {
Compress(Deltas) Deltas
}
// DeltaCompressorFunc should remove redundant changes; but changes that
// are redundant depend on one's desired semantics, so this is an
// injectable function.
//
// DeltaCompressorFunc adapts a raw function to be a DeltaCompressor.
type DeltaCompressorFunc func(Deltas) Deltas
// Compress just calls dc.
func (dc DeltaCompressorFunc) Compress(d Deltas) Deltas {
return dc(d)
}
// DeltaType is the type of a change (addition, deletion, etc)
type DeltaType string
const (
Added DeltaType = "Added"
Updated DeltaType = "Updated"
Deleted DeltaType = "Deleted"
// The other types are obvious. You'll get Sync deltas when:
// * A watch expires/errors out and a new list/watch cycle is started.
// * You've turned on periodic syncs.
// (Anything that trigger's DeltaFIFO's Replace() method.)
Sync DeltaType = "Sync"
)
// Delta is the type stored by a DeltaFIFO. It tells you what change
// happened, and the object's state after* that change.
//
// [*] Unless the change is a deletion, and then you'll get the final
// state of the object before it was deleted.
type Delta struct {
Type DeltaType
Object interface{}
}
// Deltas is a list of one or more 'Delta's to an individual object.
// The oldest delta is at index 0, the newest delta is the last one.
type Deltas []Delta
// Oldest is a convenience function that returns the oldest delta, or
// nil if there are no deltas.
func (d Deltas) Oldest() *Delta {
if len(d) > 0 {
return &d[0]
}
return nil
}
// Newest is a convenience function that returns the newest delta, or
// nil if there are no deltas.
func (d Deltas) Newest() *Delta {
if n := len(d); n > 0 {
return &d[n-1]
}
return nil
}
// copyDeltas returns a shallow copy of d; that is, it copies the slice but not
// the objects in the slice. This allows Get/List to return an object that we
// know won't be clobbered by a subsequent call to a delta compressor.
func copyDeltas(d Deltas) Deltas {
d2 := make(Deltas, len(d))
copy(d2, d)
return d2
}
// DeletedFinalStateUnknown is placed into a DeltaFIFO in the case where
// an object was deleted but the watch deletion event was missed. In this
// case we don't know the final "resting" state of the object, so there's
// a chance the included `Obj` is stale.
type DeletedFinalStateUnknown struct {
Key string
Obj interface{}
}
|
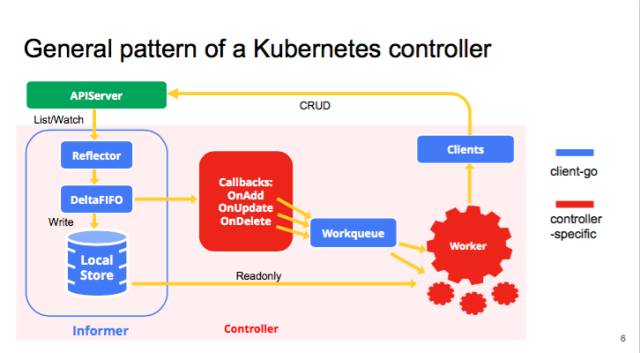
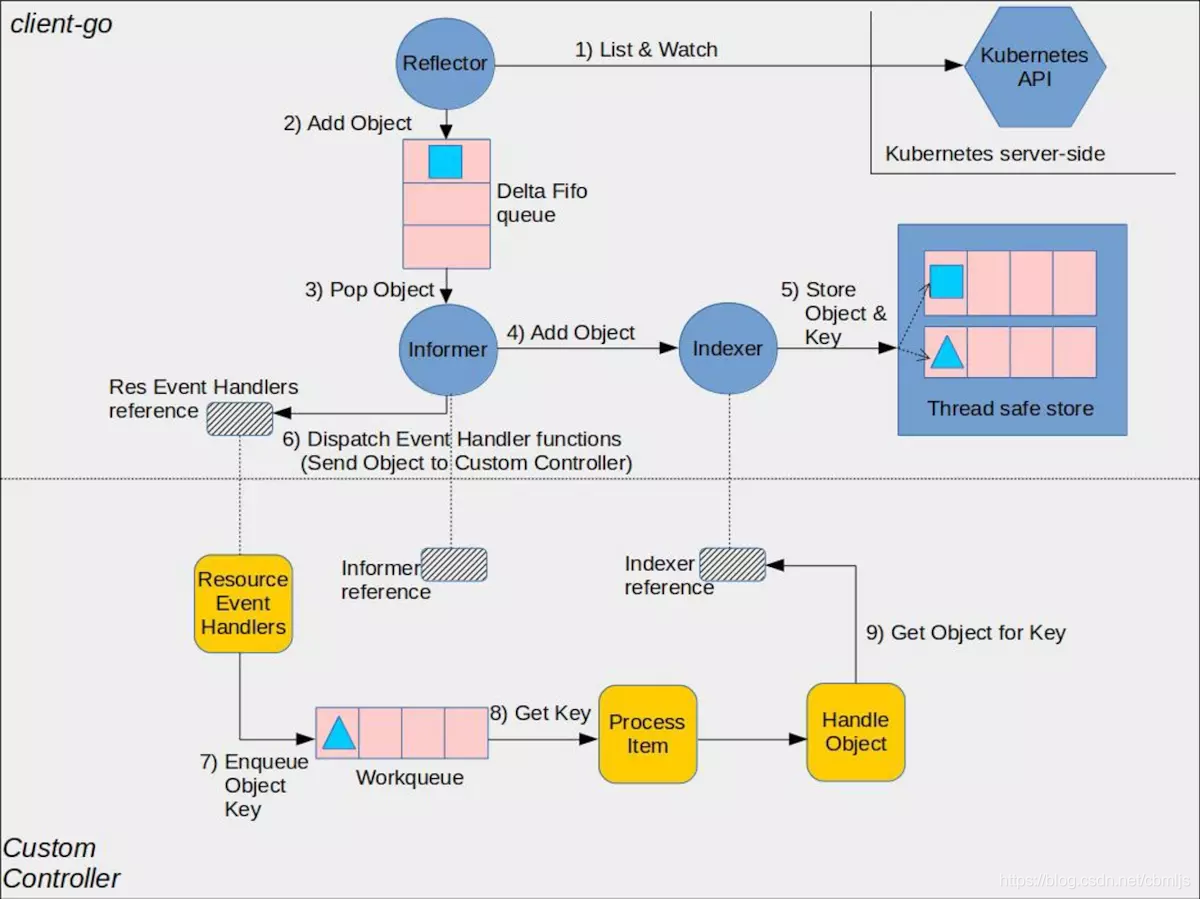 由上可看出,进行k8s controller开发时,对以下几点进行定制开发:
由上可看出,进行k8s controller开发时,对以下几点进行定制开发: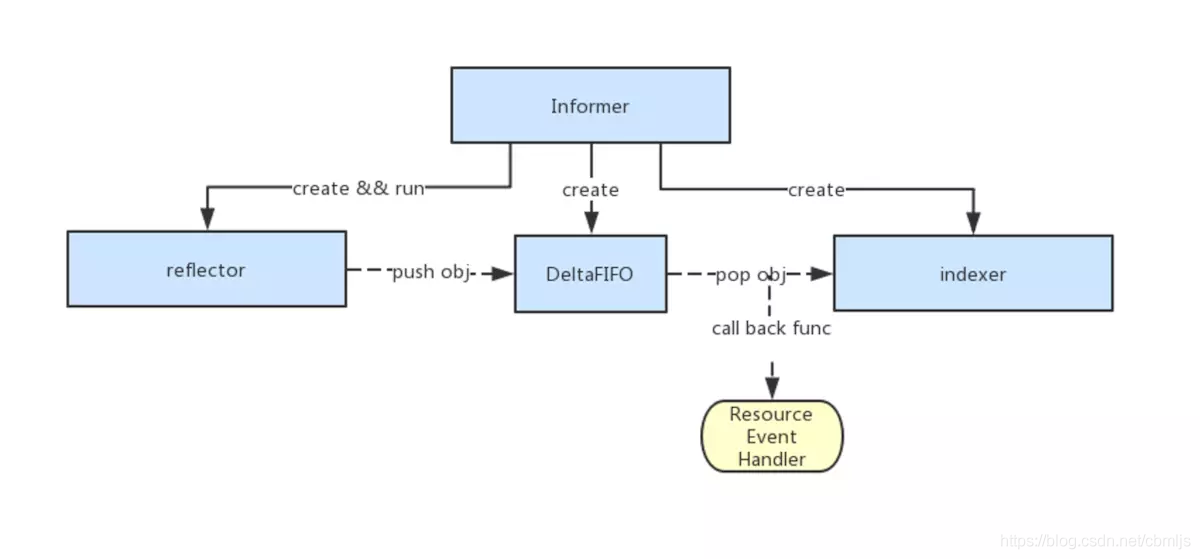
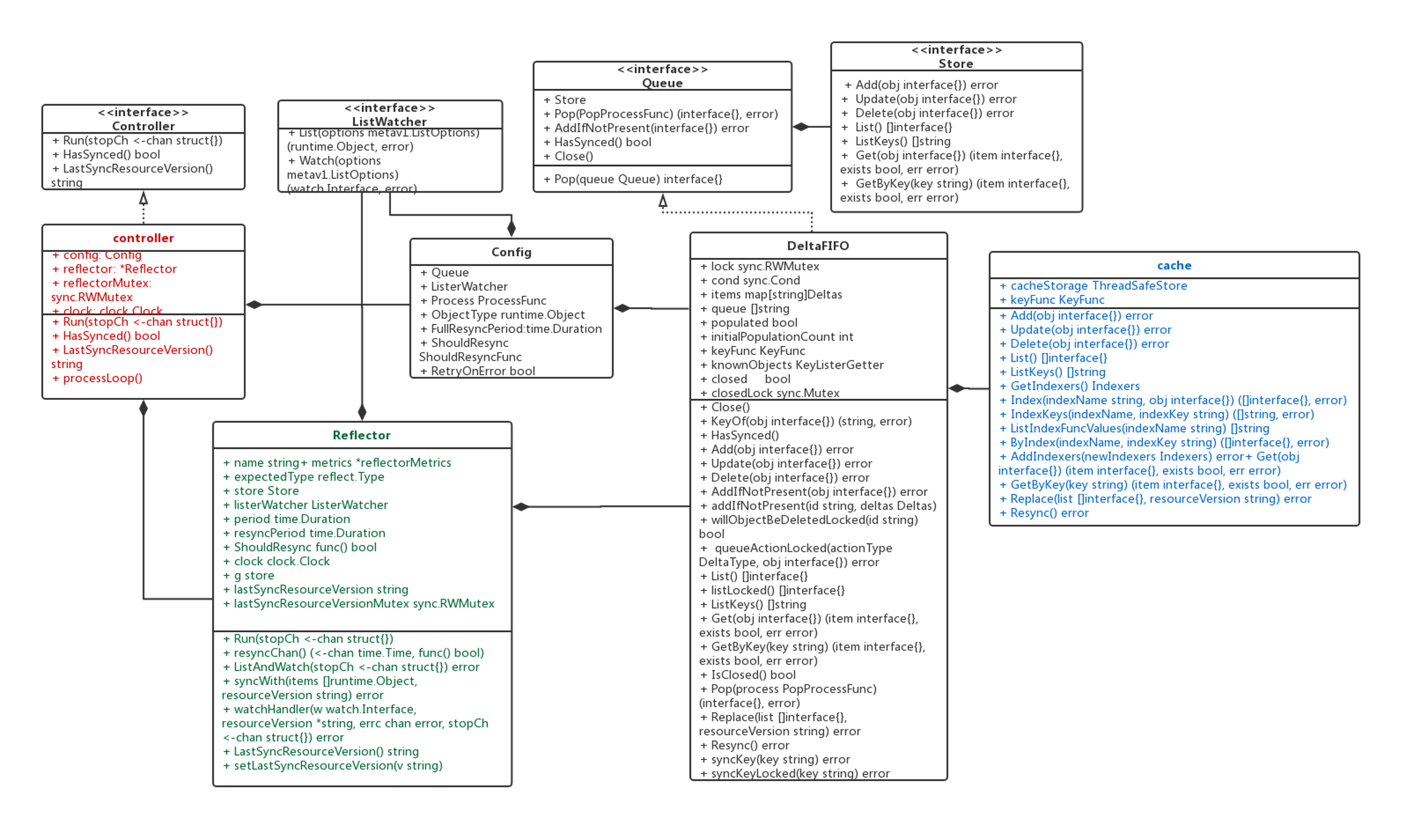
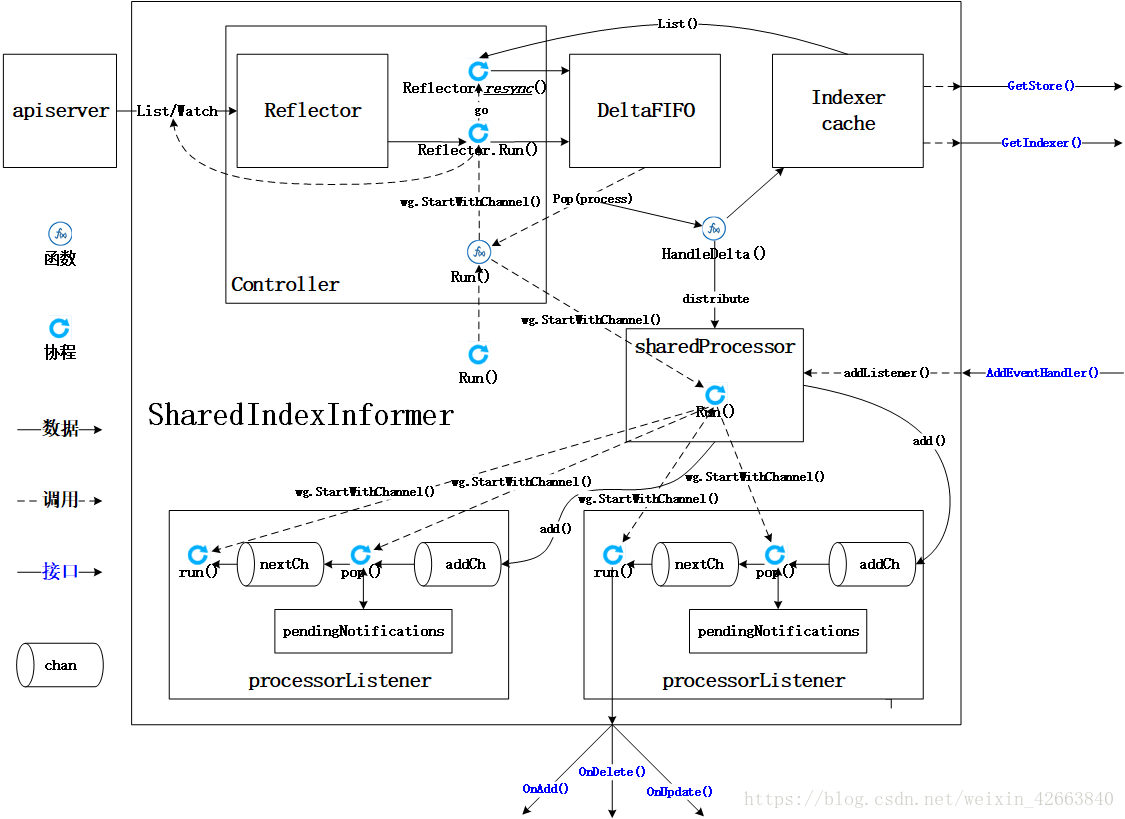
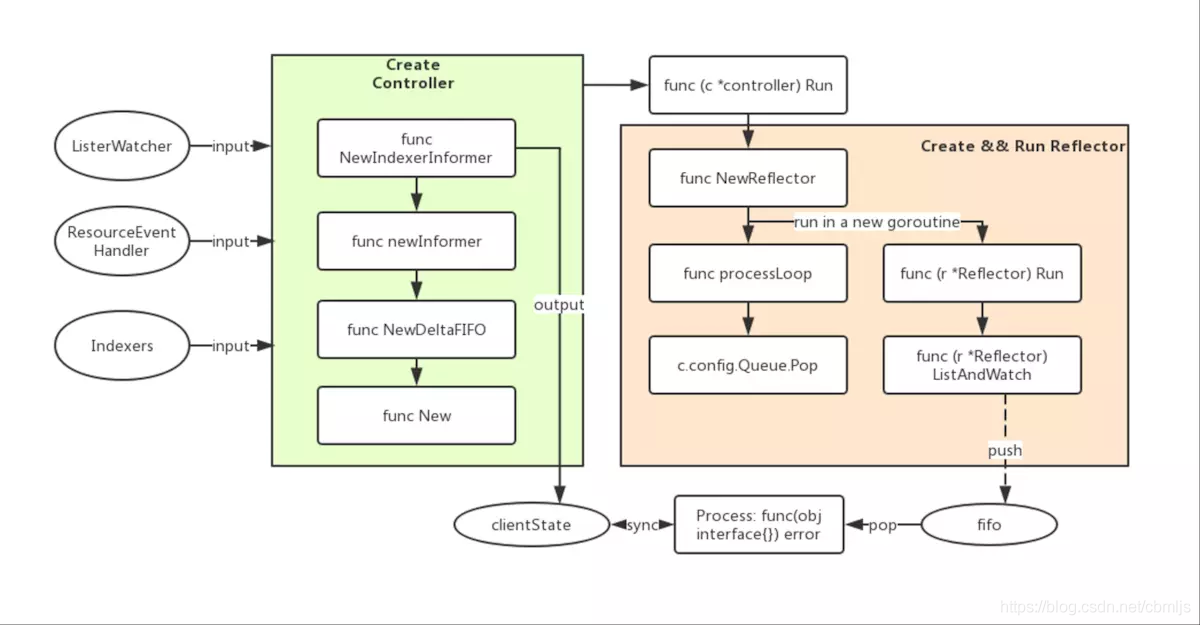 informer类图
informer类图